Table of Contents
Thankfully, writing tests for a codebase is now a commonly adopted practice in tech: it helps to ensure that the code behaviors remain as expected over time, avoids regressions, and overall improves quality and stability. Developers who write tests quickly come to the following questions: “Am I doing this right? Should I add more tests? Am I writing too many tests?”. The code coverage metric emerged as a tentative to answer those questions.
If you read a bit about code coverage already or experienced it, you are probably aware that it is a quite controversial metric, and that it might not provide relevant feedback about the quality of the tests. In this article, I share my experience on this topic and discuss diff coverage, an alternative I am more in favor of, as a great tool for developers to self-review their work and self-improve as well.
Code coverage: a controversial metric for test quality
Code coverage is the percentage of lines of code that are executed while running the tests. Most test tools (PHPUnit, Pytest, Mocha, …) can output code coverage reports after a test run: those are files listing all lines of codes and how many times they have been executed during the test run. Code coverage can therefore be used as a metric to understand how much of the codebase is covered by the tests. Instinctively, the higher the percentage, the safer the codebase. Unfortunately, it is not that simple.
What value should we consider good enough? Is 50% acceptable? Or should we aim for 100%? It depends. For instance, on an old codebase to which tests were added along the way, there are probably old untested files so the percentage might be low. And maybe this is acceptable, as long as you don’t modify those files and how they are used. Setting an arbitrary target can then have unwanted impacts: Forcing developers to cover more lines can lead to implementing irrelevant tests that will make later changes more painful.
Even worse, one can easily trick the metric by implementing dumb tests that run many lines, but are always passing! Just because a line is covered does not mean it is behaving as expected: maybe the test running it does not check correctly the behavior anyway.
So focusing on code coverage can distract developers from implementing meaningful and business-oriented tests. For those reasons mainly, code coverage is often considered an irrelevant metric to focus on. It can be good to have a look at it from time to time to spot trends: a sudden drop in code coverage might indicate that recent developments are not well covered for instance. However, the information provided by this metric is quite limited and does not really answer the key question: are you building a robust test suite that will ensure the application is properly working?
Diff coverage: a first step toward an answer
I don’t think there is an easy way to measure and assert the quality of a test suite, and as discussed above, code coverage is not really helping. But it does not mean nothing can be done.
I am convinced that allowing developers to get feedback on the test suite quality in the context of their changes is a promising approach: instead of providing a measure across the whole codebase, feedback focused on the ongoing or latest changes is much more impactful. The context is fresh in the developer’s mind and they can probably leverage this feedback now as they are working on this part of the code currently. This also goes in the direction of self-service and continuous learning that ultimately empowers engineering teams!
Diff coverage is a very interesting tool that aligns with this philosophy. Diff coverage can be computed in the context of a code change (a commit, a pull request): it is the percentage of modified lines covered by tests. So this is very similar to code coverage, but on a restricted set of lines, in a focused context. Therefore, it still suffers from most of the drawbacks of code coverage we discussed above and it should not be taken as an absolute answer either.
For this reason, I don’t think diff coverage can be an interesting metric to follow the codebase quality. But as it is embedded in a specific context, it can be used as feedback for the developers themselves. Moreover, if you are submitting not-too-big PRs, diff coverage can be easily analyzed visually. Let’s take the following example:

This is a diff coverage report on a pull request adding a filter in a WordPress plugin, from Codacy visual diff coverage report. Thanks to it, one can quickly identify the case where the filter returns another type than int is not covered by a test. This is great visual feedback for developers to easily check what is covered already: It can be hard to identify what is being covered by reading the tests; here we have an easy way to visualize it.
Note that the valuable input here is not the coverage percentage, but rather the detail of uncovered lines. Therefore, there is no gate or target value to reach, but this encourages developers to review the report and use their critical thinking:
- Was it expected that this line would not be covered? Maybe a test was designed to cover it but did not run as expected? Diff coverage reports can help identify issues in the tests themselves.
- Should the uncovered lines be covered? Some lines are important to cover, others are not. Without providing a direct answer, the diff coverage report brings attention to the quality of the test suite and enables developers to focus on it and consider whether or not more work is needed.
Having experienced diff coverage reports in pull requests in my teams, I have seen it enabling valuable discussions about the test suite, that did not happen before. One perk of this approach is that it eases the review of the tests in the pull request review process: developers can quickly identify how the tests behave on the code. As a result, I witnessed discussions between developers suggesting adding or reworking some tests, and eventually PR authors themselves proactively pushed additional commits to tackle the diff coverage reports early in the process.
Overall, diff coverage is not the ultimate answer to measuring the quality of the test suite; the value itself is not very relevant. However, I found great benefits in the report itself for each pull request as a way to shed light on the test suite quality and enable the discussion around it. Ultimately, this is a powerful tool to enhance the quality of the test suite.
You can read more about diff coverage and the code review process at WP Media in our public Engineering handbook!
How to compute and report diff coverage
In the following, I will showcase two ways of reporting diff coverage with your CI:
- using Codacy which is an online tool that analyzes coverage reports and your repository ;
- using diff_cover, a Python tool that computes and reports diff coverage from a diff and a coverage report.
For both methods, you first need to get a coverage report.
Coverage reports
Most test tools have options to output a coverage report. Several formats exist, but they basically list all the lines in your codebase and associate a counter to each of them. This counter is incremented every time the line is executed while performing the tests. Therefore, coverage reports allow you to identify what part of your code is covered by tests and how many tests trigger each line. The following excerpt showcases the typical content of a coverage report. Some lines are covered (1, 2, etc.), some are not (3, 5, 7, 8), and some are not reported (4, 6, 9, 10) maybe because they are part of a multi-line statement, comments or blank lines.
<?xml version="1.0" ?>
<coverage version="7.3.0" timestamp="1725444369214" lines-valid="1321" lines-covered="1261" line-rate="0.9546" branches-covered="0" branches-valid="0" branch-rate="0" complexity="0">
<!-- Generated by coverage.py: https://coverage.readthedocs.io/en/7.3.0 -->
<!-- Based on https://raw.githubusercontent.com/cobertura/web/master/htdocs/xml/coverage-04.dtd -->
<sources>
<source>/Users/mathieu/Documents/Github/diff_cover-fork/diff_cover</source>
</sources>
<packages>
<package name="." line-rate="0.949" branch-rate="0" complexity="0">
<classes>
<class name="__init__.py" filename="__init__.py" complexity="0" line-rate="0.5556" branch-rate="0">
<methods/>
<lines>
<line number="1" hits="1"/>
<line number="2" hits="1"/>
<line number="3" hits="0"/>
<line number="5" hits="0"/>
<line number="7" hits="0"/>
<line number="8" hits="0"/>
<line number="11" hits="1"/>
<line number="12" hits="1"/>
<line number="13" hits="1"/>
</lines>
</class>
</classes>
</package>
</packages>
</coverage>The following example runs pytest and outputs an XML coverage report:
pytest --cov=. --cov-report=xml The following example uses PHPUnit and is slightly more advanced as several test runs are executed and individual reports are merged with phpcov, typically to account for unit and integration test coverage:
phpunit --testsuite unit --configuration tests/Unit/phpunit.xml.dist --coverage-php tests/report/unit.cov
phpunit --testsuite integration --configuration tests/Integration/phpunit.xml.dist --coverage-php tests/report/integration.cov",
phpcov merge tests/report --clover tests/report/coverage.cloverThose lines can directly be executed during your CI while you run the tests. Note however that computing code coverage introduces overhead and it can slow down your CI. Therefore, consider where to compute the coverage reports. For instance, if you run your test suite with several PHP versions, you probably need coverage from only one run.
Diff coverage with Codacy
Codacy is an online tool that can analyze your repositories, branches, pull requests and commits. Additionally, you can send coverage reports for different commits and Codacy will compute the diff coverage from there, as well as other metrics such as global coverage evolution for instance.
Codacy is free for public repositories and provides an easy and accessible way to compute and read diff coverage reports, as displayed in this screenshot:
Once you have a coverage report in your CI running on a pull request for example, Codacy makes it easy, through a GitHub action, to upload that report with the needed context so that the processing can be done online, and then reported directly within the PR. You can even add quality gates to fail the CI if they are not met, which can be a great tool to bring your team to pay more attention to it.

Diff coverage with diff_cover
Codacy might not fit your needs: it is not free for private repositories, and it is yet another tool you have to connect to. diff_cover is an open-source Python tool that you can run in your CI as well, or even locally to get diff coverage reports. While the integration is a bit more complex, it is nothing unmanageable.
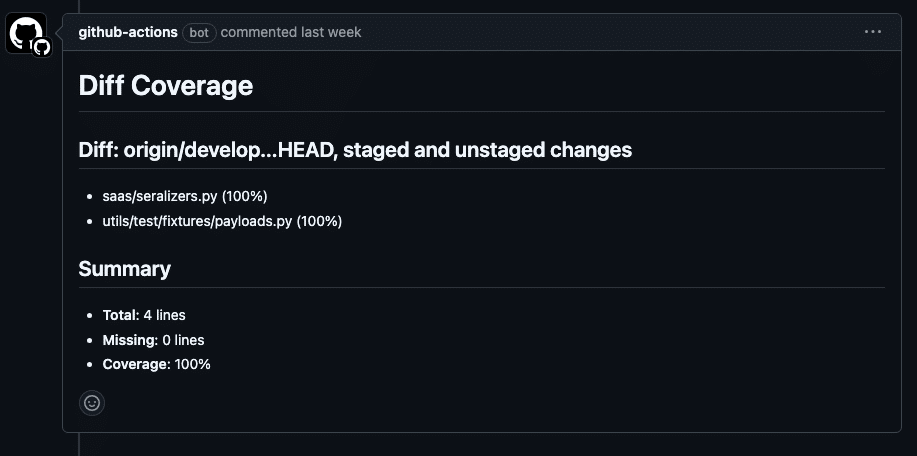
diff_cover needs to be provided with a coverage report and the reference of the branch to compare the current code against. Additional options are also available. Here is an example from a CI at WP Media that produces a behavior similar to the one from Codacy:
- We install
diff_cover; diff-coverprovides the diff coverage percentage and a markdown report;- we remove all previous coverage reports from the pull request comments;
- then we add the new report as a pull request comment;
- and finally, we fail the CI if coverage is below the threshold passed as an argument to
diff-cover.
- name: Install dependencies
run: pip install diff_cover
- name: Generate diff-coverage report
if: github.event_name == 'pull_request'
run: |
diff-cover coverage.xml --compare-branch=origin/${{ github.base_ref }} --markdown-report diff-cover-report.md --exclude test*.py --fail-under=50
echo "DIFF_COVER_EXIT_STATUS=$?" >> $GITHUB_ENV
shell: bash
- name: Delete previous diff-cover reports
if: github.event_name == 'pull_request'
uses: actions/github-script@v6
with:
script: |
const { data: comments } = await github.rest.issues.listComments({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number
});
for (const comment of comments) {
if (comment.user.login === 'github-actions[bot]' && comment.body.includes('# Diff Coverage')) {
console.log(`Deleting comment with ID: ${comment.id}`);
await github.rest.issues.deleteComment({
owner: context.repo.owner,
repo: context.repo.repo,
comment_id: comment.id
});
}
}
env:
GITHUB_TOKEN: ${{ secrets.GIT_TOKEN }}
- name: Post diff-cover report to PR
if: github.event_name == 'pull_request'
uses: actions/github-script@v6
with:
script: |
const fs = require('fs');
const comment = fs.readFileSync('diff-cover-report.md', 'utf8');
await github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: comment,
});
- name: Fail job if coverage is below threshold
if: github.event_name == 'pull_request'
run: |
if [[ "${{ env.DIFF_COVER_EXIT_STATUS }}" -ne 0 ]]; then
echo "Coverage below threshold; failing the job."
exit 1
fi
shell: bashOne benefit of diff_cover is that it can work with any language as long as you have coverage reports available, allowing you to reproduce consistently the check, gates, and reports across all your repositories.

I am Mathieu Lamiot, a France-based tech-enthusiast engineer passionate about system design and bringing brilliant individuals together as a team. I dedicate myself to Tech & Engineering management, leading teams to make an impact, deliver value, and accomplish great things.