Table of Contents
A QA best practice to reduce the risk of releasing
In some companies, releasing a new service version can be a feared moment: will it work as expected or will everything go down? Even with a significant testing process on a staging environment, going to production can be dreading as the context can drastically change: service load, unexpected edge cases, etc. Those conditions can be challenging to replicate in a staging environment, especially if you don’t have a dedicated team in charge of such experiments.
But a new release should be a celebration, or even better, a non-event for teams used to deliver to production daily. Shadow testing, also called traffic mirroring, is one approach that can help bridge the gap and reduce the risks of a release by testing it under “production conditions”, without writing more tests or manually generating scenarios.
A test environment in the shadow of production servers
The concept of shadow testing is to duplicate some of an app’s traffic in production and route it to a testing environment, called a “mirror environment”. Responses and/or metrics of interest from both the production and mirror environments must then be collected to compare results and behaviors.
This allows us to test a new version or a code change against real-world traffic and spot differences compared to the current production code; such as changes in responses, response code rates, resource usage, error rates, etc. Additionally, one can easily identify scenarios in which the new version behaves differently to assess if this is expected or a regression, and eventually reproduce the issue. Finally, compared to canary releases, shadow testing allows testing in a production context without impacting any users with frictions, regressions, or downtimes.
It is crucial that the mirror environment does not affect any states in production (such as user or account data); therefore it is mostly useful for stateless parts of the code, even though it can be adapted for stateful apps too.
Shadow testing in practice
Setting up shadow testing manually
To illustrate this QA practice, let’s take the example of WP Rocket SaaS: Users can send requests containing a URL to this service, so that it browses the URL, perform various optimizations on it and store the results. Each page to optimize is called a job.
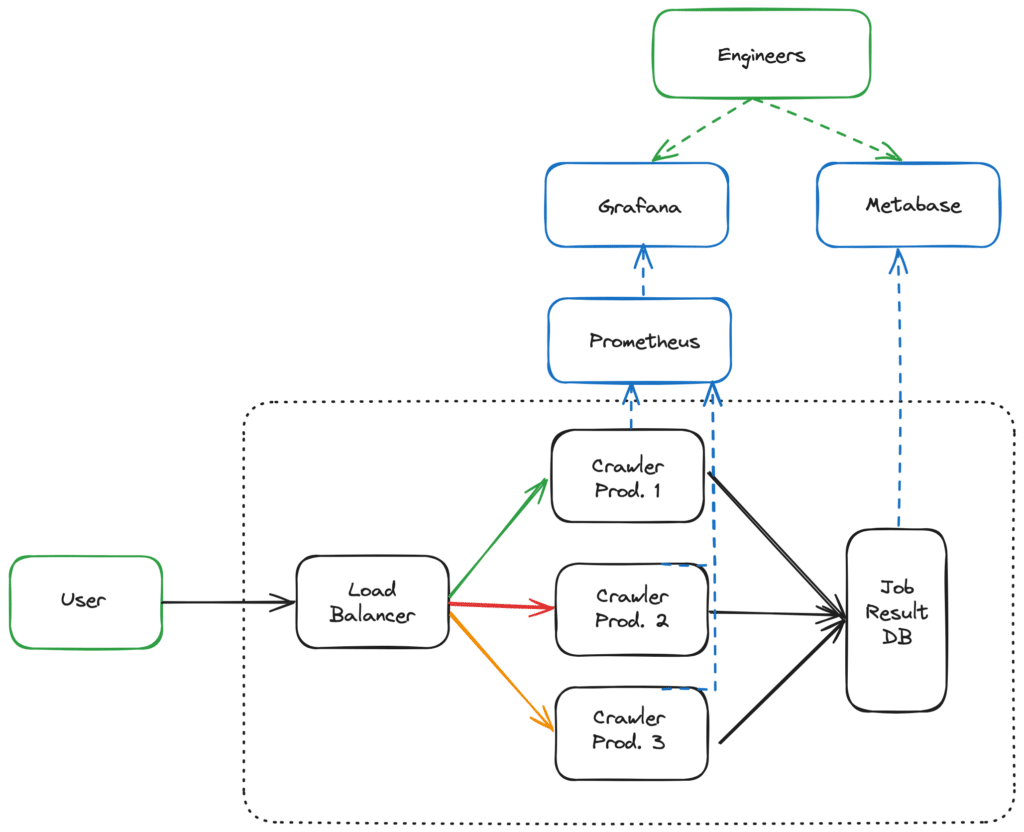
The “crawler”, ie. the service in charge of browsing a page and performing the optimizations on it is critical: it has many dependencies, is resource intensive as it performs 20.000 jobs per minute, and is updated weekly or even daily. Shadow testing is a great approach to reduce risks about scaling as well as spotting regressions on edge cases in this context. To implement it, we had to:
- Add a duplication logic in the load balancer: some jobs are flagged as mirrored, and sent to both the production and mirror crawler.
- Adapt existing Grafana dashboards to compare production and mirror crawler metrics, such as resource usage and error code rates.
- Build queries and dashboards in Metabase to compare production and mirror job results and report differences. This application is a great example of how BI & Data tooling can empower your company.
- Adapt our CI/CD to be able to deploy a specific GitHub commit to the mirror environment.
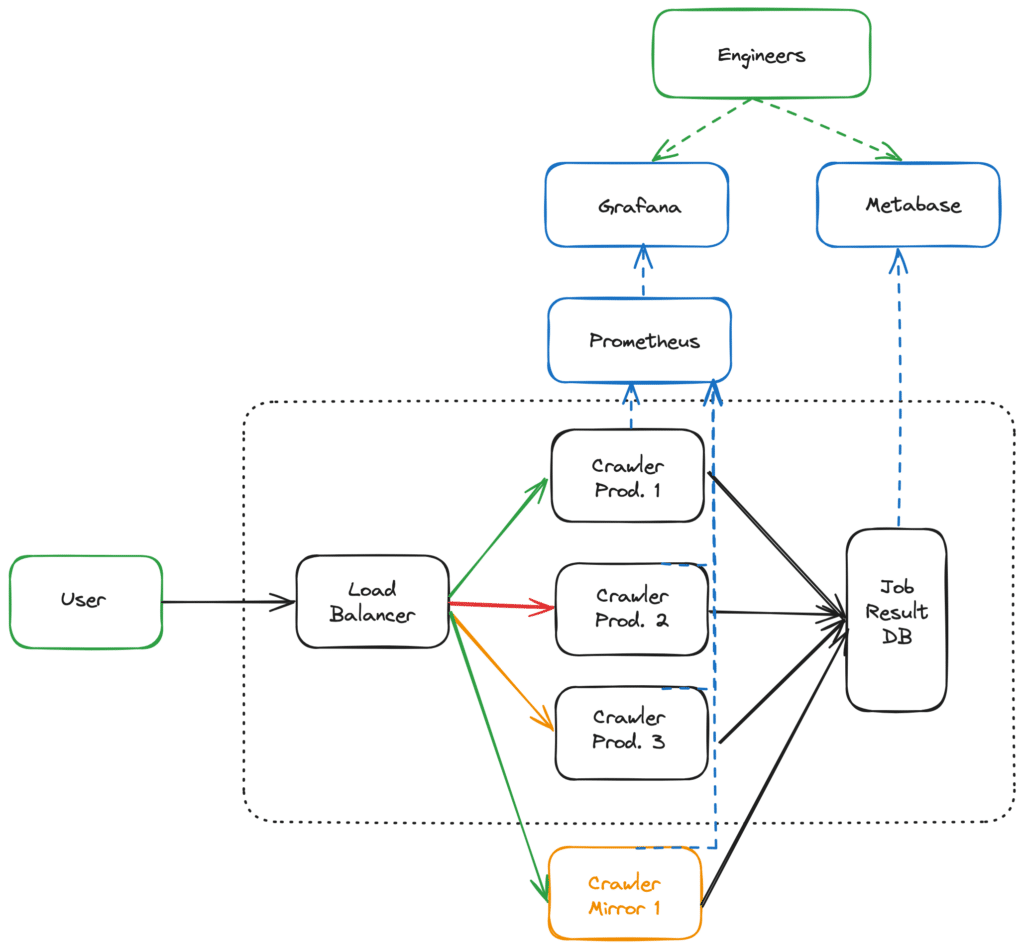
For code changes that need testing “at scale”, our teams can now quickly deploy the change to the mirror environment. After a few minutes, they can access the results of the comparison on Grafana and Metabase:

How shadow testing saved us
Since we use this best practice on WP Rocket SaaS services, several regressions and issues were spotted early on and fixed before reaching production. They would have likely gone through if we did not use a mirror environment.
At its core, the crawler leverages Puppeteer to manage web browser instances. We extensively relied on coverage methods for JS and CSS optimization. However, those methods became much more resource-intensive starting with v20.9, leading to a 50% CPU usage increase for our application. This was spotted thanks to the shadow testing approach, as we immediately saw a discrepancy in CPU usage that would not have been easily seen with a staging approach or could have caused slow-downs or even downtimes if released to production. Spotting this early on allowed us to release the Puppeteer dependency update along with another approach for our optimizations that does not rely on the impacted coverage methods.
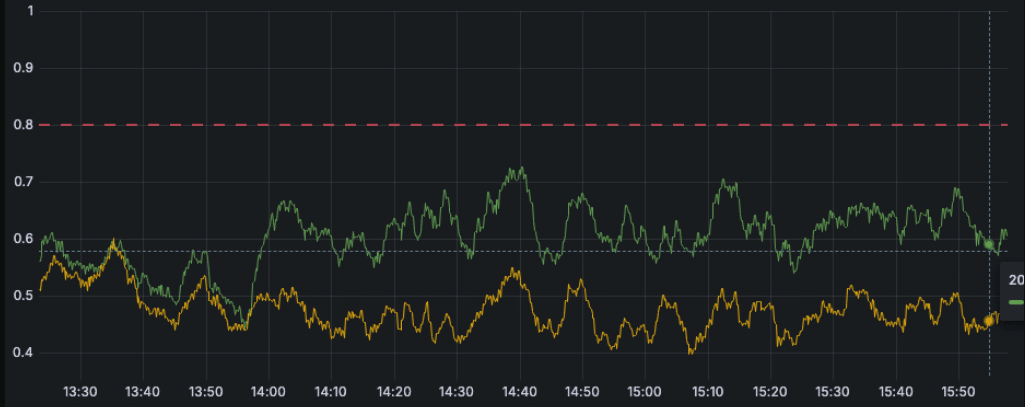
On multiple occasions, we have been able to spot the introduction of regressions or unexpected behavioral changes thanks to shadow testing. This is also very useful for evaluating at-scale performances of new approaches without impacting any customers.
Tools to set up shadow testing
While this approach can be set up manually, as in the previous example, some libraries and tools exist to do the job for you. One of them is Diffy which handles request duplication, forwarding, and response selection for you as long as you have a production and a mirror environment up and running.
A nice caveat is Diffy’s ability to have multiple production environments and compare their responses as well, to evaluate how non-deterministic your app is. Diffy uses this data to adjust its thresholds to trigger an alert that the new code might introduce an issue. To illustrate this, let’s get back to our previous example: browsing a page is not fully deterministic. Some network or server issues could occur and result in the crawler seeing a page different than the expected one, with a missing image for instance. Hence, a given job could return different outputs without changing the code of the service itself. Diffy tries and remove this effect from its comparison between current and new versions of the code.
Off-the-shelf solutions such as Diffy can be a great choice to apply to stateless API endpoints, which are request-response based. If the architecture of your service is more specific, you might prefer going with a custom implementation.
Staging vs. Shadow testing vs. Canary releases
While staging environments are very useful for developers and QA engineers to run manual and automated sets of tests, it can be challenging to cover all production edge cases and “at scale” behaviors. Shadow testing is a good complementary approach as it allows one to observe the behavior of the new version at scale and compare it directly with the production version. Both staging and mirror environments are safe as they do not impact production and end-users. Developers and QA engineers can also easily use them if they are properly integrated into deployment pipelines.
Canary releases are quite different as they directly impact end-users, to retrieve early feedback from the first users. Adding shadow testing before canary releases allows for the reduction of error risks and minimizes the potential impacts for early users. As a result, canary releases are mostly used for feedback about UX and friction, as most technical issues have already been addressed.
To summarize, shadow testing is a great complement to testing on staging environments and canary releases: it allows testing new versions in conditions and with use cases identical to production without impacting end-users. It is an efficient way to identify early on technical defects as long as it is well integrated into the development cycle with deployment flows and ready-to-use dashboards to compare results and behaviors of production and mirror environments.
Featured image by wirestock on Freepik

I am Mathieu Lamiot, a France-based tech-enthusiast engineer passionate about system design and bringing brilliant individuals together as a team. I dedicate myself to Tech & Engineering management, leading teams to make an impact, deliver value, and accomplish great things.