Table of Contents
Increasing efficiency: the common engineering leader’s mission
As I became in charge of the engineering departments of WP Media and RankMath at different points in my career, I faced a similar request: to improve the engineering team’s efficiency. The brief seemed straightforward – help the team deliver more features, faster. But the real bottlenecks aren’t always where you expect them to be.
My first weeks were spent shadowing developers, understanding their daily routines, and identifying what consumed their time. A pattern quickly emerged though it wasn’t about code quality, technical debt, or deployment processes as one could initially suspect. The real-time sink was hiding somewhere else: support ticket escalations.
“I spent my morning helping support with a customer issue”, one developer would say. “Remember that Slack thread from last week about the caching problem? It came back again.”, mentioned another. “I’m not sure if I should be working on the new feature or handling these urgent customer issues”, a third developer confessed during our daily meetings.
The Hidden Costs of Poor Escalation Management
This wasn’t just about interrupted developers. Our support team was struggling to provide ETAs to customers. Tickets that needed technical expertise would sometimes vanish into the depths of Slack channels. Customers were growing frustrated with long wait times and unclear status updates. Even worse, we kept seeing the same issues being escalated repeatedly because solutions weren’t being documented and shared.
The cost wasn’t just in team morale or customer satisfaction. Our development velocity was taking a hit, and our ability to improve our products was suffering. We were stuck in a reactive cycle, constantly fighting fires instead of preventing them.
Team Agreements for a Better Escalation System
Through months of experimentation and learning from our mistakes, I discovered that the key to successful escalation management isn’t just about having sophisticated tools – it’s about creating an ecosystem where information flows naturally and everyone knows their role.
Open & clear communication
The first improvement in our communication flow was straightforward: centralize all escalation discussions in a dedicated Slack channel. Moving away from scattered direct messages and random channel discussions to a single channel with threaded conversations was like turning a noisy party into organized round-table discussions. Each escalation has its own thread, making it easier for everyone to follow specific issues without the noise of unrelated conversations.

Define the needed information
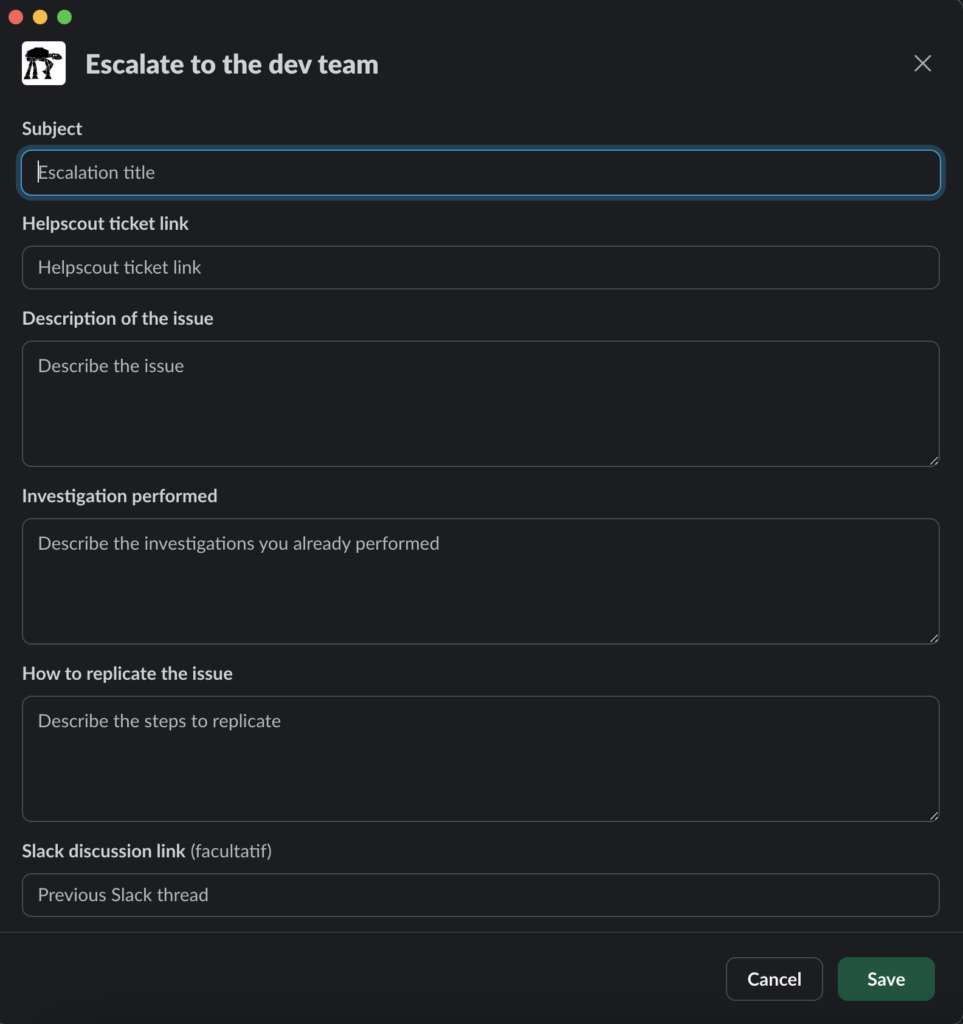
Then, I observed many escalations threads to better understand the interactions between the support team and the developers. It came out quickly that the first messages on escalation threads were often about getting the environments, credentials or steps to reproduce. While this is acceptable in a synchronous workflow, we were operating in asynchronous companies: the support teammate might be off when the developer picks up the escalation, so they would have to wait another day to get the needed basic information.
We created a Slack workflow with a structured form for escalations, ensuring all necessary information was collected upfront. Each escalation had to include reproduction steps, access to an environment with the issue, and previous investigation attempts. No more back-and-forth asking for basic details. Developers could now start investigating issues immediately instead of spending time gathering basic information. It was like giving mechanics a complete diagnostic report before they even look at the car – efficient and straightforward.
Define the goals
Just as important as the process itself was establishing clear expectations about what an escalation could achieve. While it may seem obvious for developers and product teams, it is not necessarily known that bugs might not always need to be fixed immediately: some incompatibilities might be accepted, or some frictions might be known but not prioritized to dedicate the bandwidth for more impactful work. To clarify expectations from the get-go and avoid the use of escalations as a parallel prioritization process, we made it explicit that escalations were for investigations and operational support, not for triggering immediate development work. When a developer investigated an escalated issue, there were three possible outcomes:
- Identify the root cause and provide an immediate solution that the support team or customer could implement;
- If the issue requires development work, document the investigation findings (including codebase references and reproduction steps) for the product team to prioritize, and if possible, provide a temporary workaround;
- For operational issues, perform the necessary actions according to established procedures.
This clarity was crucial – it prevented frustration from both teams and customers by setting the right expectations upfront. Support team members knew not to escalate known issues awaiting development, and customers understood that some solutions might require future product updates rather than immediate fixes. As a result, it prevented developers from working on tasks not aligned with the priorities of the product team and of the company.
Importantly, while escalations didn’t trigger immediate development work, they were valuable input for the product team’s prioritization process. Each thoroughly documented escalation helped build a clear picture of customer pain points and technical issues that needed addressing. This information became instrumental in shaping our product roadmap and bug-fixing priorities.
Focus on what matters thanks to automated tracking
However, we soon hit another wall. While having all escalations in one channel with dedicated threads helped with focused discussions, it created a new challenge: visibility. As the number of threads grew, it became increasingly difficult to know which escalations were still active, which were resolved, and which needed immediate attention. Scrolling through a channel to find that one urgent thread from last week became a daily struggle. It was like having a well-organized filing cabinet but no index – everything had its place, but finding what you needed was still a challenge: We needed a single source of truth for tracking the status of each escalation.
Depending on the team’s preferred tools, we automatically added each escalation to either a GitHub board or a Slack list. Each escalation became a trackable entity with status updates, ownership, and due dates. When a ticket’s status changed or approached our response time limits, the system automatically notified relevant team members in their corresponding Slack threads.
What’s particularly noteworthy is that achieving this doesn’t require complex or expensive tools. At WP Media, we built TB-TT (see dev_team_escalation related methods), a simple custom application to handle our automation needs based on Slack webhooks and API, as well as GitHub API. At RankMath, we accomplished similar results using just Slack workflows and lists. The key is not the sophistication of the tools, but rather keeping everything within environments your team already knows and uses daily.

Those tracking boards became an integral part of our daily team routine. Every morning during our standup meeting, we would review ongoing escalations alongside our regular development tasks. If we noticed an escalation taking longer than expected or lacking an owner, we could immediately adjust our priorities or redistribute work.
Automation played a crucial role in reducing overhead and eliminating manual tasks, allowing both support and development teams to focus on what truly matters: investigating and fixing user issues. It removed the cognitive load of “Where do I post this?” or “Who should I notify?” from the equation. The overhead of the process became almost invisible, which is exactly what we wanted and we could focus on reinforcing why escalations deserve priority attention. This wasn’t just about process efficiency – it was about living our company’s “users first” value.

The Unexpected Benefits of Getting Escalations Right
As we spent a few months with our new process, we quickly realized that many escalations were very similar: related issues were being raised repeatedly and we realized there was an opportunity to improve our support team responses so that they could handle those already-seen issues themselves.
Knowledge sharing became another cornerstone of our approach. We established a simple yet effective rule: developers must clearly explain their resolution process in the Slack thread once an issue is solved. This explanation should include any use of specific debug tools. This wasn’t just about saying “it’s fixed” – it meant detailing the investigation steps, the root cause, and the solution implemented. It shifted our mindset from “fix and forget” to “fix and share.”
This systematic documentation served multiple purposes. Support team members could immediately add these explanations to their knowledge base, making the information readily available for future similar cases. They started hearing about the developers’ debug methodologies and the tools they were using, so they started using them directly. Support team members could now handle similar issues independently, referring to previously documented solutions.
Key Elements of an Effective Escalation System
The impact of these changes was profound. Our escalation volume began to decrease as the support team built up their knowledge base. Response times improved dramatically, and both teams reported higher job satisfaction. But perhaps most importantly, our customers noticed the difference. WP Rocket’s consistently high ratings on Trustpilot (4.8 out of 5 with over 2,400 reviews) often highlight the quality and efficiency of our support process. This wasn’t just about fixing technical issues – it became a foundation of our company’s success.
Looking back at my experiences at both WP Media and RankMath, I would summarize the key elements that make an escalation process successful as follows:
- Centralized Open Communication: A dedicated channel where all escalations are discussed, with threaded conversations for focused discussion.
- Clear Escalation Criteria: Every team member must understand what warrants an escalation. We defined clear expectations: escalations are for investigations requiring technical expertise or specific operations, not for feature requests or known issues awaiting prioritization.
- Well-Defined Outcomes: Everyone must understand what an escalation can and cannot achieve. While escalations don’t trigger immediate development work, they provide valuable documentation and context that helps the product team prioritize future development efforts.
- Clear Response Expectations: Defined SLAs for first response (24 hours in our case), with automated reminders to meet these commitments.
- Clear Tracking & Visibility: A single source of truth for tracking escalations, whether it’s a GitHub board or a Slack list, reviewed daily during team meetings.
- Automated Notifications: Simple automations keeping everyone informed about status changes and approaching deadlines.
- Structured Information Gathering: Automated forms ensuring all necessary details are collected before an escalation reaches developers.
- Systematic Knowledge Sharing: Mandatory documentation of solutions in a format that can be easily added to the support team’s knowledge base.
The goal isn’t to build the most sophisticated system – it’s to create a process that makes life easier for everyone involved while ensuring our users get the support they deserve. Often, the simplest solutions, built around your team’s existing workflows and tools, are the most effective. While not every escalation leads to immediate code changes, the insights gathered through this process become invaluable in skilling up your teams, shaping the product’s evolution, and prioritizing improvements that matter most to our users.
Paying attention to what was driving the teams off-track helped identify the need for a refined escalation process, and for the follow-up improvements we did. This is one of the usual suspects when a team struggles with focus & delivery, along with technical debt, DX, and clear goals for alignments, to list just a few.
Featured image by www.freepik.com

I am Mathieu Lamiot, a France-based tech-enthusiast engineer passionate about system design and bringing brilliant individuals together as a team. I dedicate myself to Tech & Engineering management, leading teams to make an impact, deliver value, and accomplish great things.