Table of Contents
SaaS enables data-oriented companies
I don’t know any fellow Tech workers that never heard about Software-as-a-Service (SaaS): a large majority of us work in companies that either sell SaaS, either considering moving from traditional software to SaaS. While some implications are often well understood, such as recurring revenues, getting the best out of SaaS requires companies to operate many more changes than just changing their codebase. I experienced several changes induced by SaaS and to make a whole company data-oriented is probably the most impactful to me.
I had the opportunity to work in companies in different states of the SaaS trend: Lydia began with SaaS products and hence, was built around it from the ground up; another company I worked for just started selling AWS-compatible solutions when I joined as it was originally selling hardware-based solutions; and I recently joined WP Media that started relying on SaaS for some features of its WordPress plugins. Across those experiences, the most important differences turned out to be much more than just where the code runs and the department most impacted by the SaaS approach may not be Engineering.
In this article, I want to quickly go over how the SaaS approach gives access to more data and how all teams can use it to drastically increase their impact. I will leverage the example of a feature implemented in a product from WP Media that was implemented before I joined, and that is currently growing toward leveraging the data more efficiently. This feature allows users to send optimization “jobs” to a SaaS and fetch the results later on. When I joined, nothing in those jobs was observable: we only gathered the usual health metrics of an app such as logs, number of requests, and average processing time of a job.
Data becomes your most valuable asset
With a SaaS product, your users will have to connect to your system one way or another, instead of operating your product in their environment. The way they interact with your product is now more observable than ever. Moreover, your SaaS probably already has a part dedicated to the management of this connection with the user: login system, account management, etc. You might not have much to do to start gathering insightful data: add a few tables to your database, and start storing what happens!
In the optimization job example, we started storing job context: job parameters, user ID, the different statuses the job went through, and the associated timestamps.
Design your data as a product
You should keep in mind that this data will not be used like the internal data of your app, or your traditional software. The role of databases supporting your software is ultimately that the product behaves as expected. The data you should gather has a different role: it should make your system easily observable. Therefore, it must be easy to read and manipulate, even for someone not expert in how your system works. You should not need to know the internal processes implemented in your system to be able to leverage this data, as its main users are not your developers, but the rest of your company. Therefore, carefully designing the data model is a very valuable task.
I had good experiences approaching it as I would design a feature or a system for a product: keep in mind that your users will be your colleagues, company-wide, and focus on identifying what makes an impact, and what makes sense. Then, document your model! If your data model is well-designed and documented, all the following steps discussed in this article become effortless.
I summarized my learnings on the matter and explained the models and guidelines I usually use in this article: Designing database table: My best go-tos. Remember: “Better done than perfect”. You must try to learn, and you can always iterate to improve later on!
Make it visible
Databases and tables won’t have any impact if they are just sitting there. While companies with large enough head counts can manage to develop and maintain a custom back-office, I have great experience with BI tools like Metabase that provide no-code features to explore and visualize data, as well as SQL editor for your tech-savvy colleagues. This is what I used at Lydia and WP Media, with great results and positive feedback from most teams.
If you designed and documented your data model properly, all teams can start exploring and building meaningful dashboards: they are now equipped to extract value from the data by themselves. Congratulations, you just multiplied the impact of your data by the number of people in your company!
In the following, I will discuss a few ways to leverage this data in various departments.
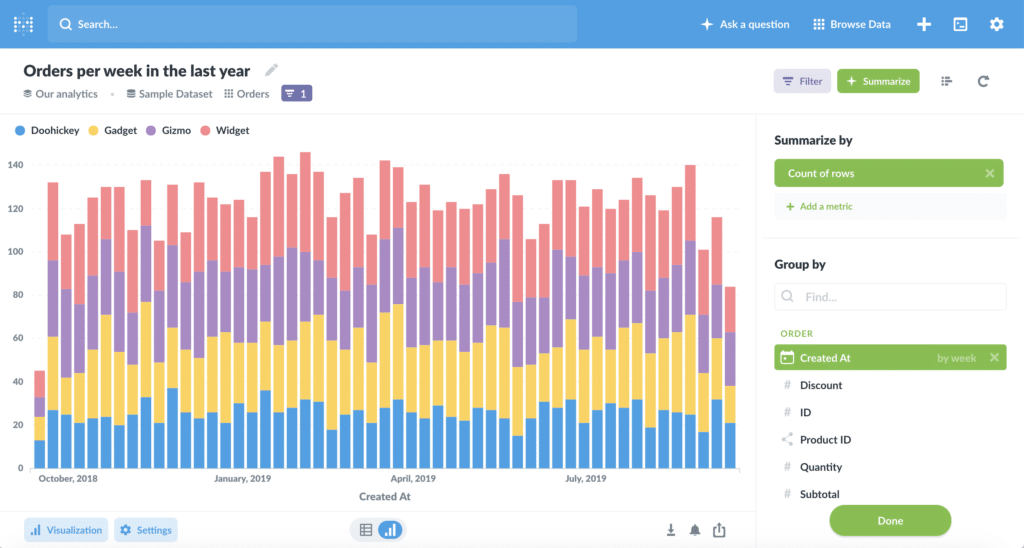
Customized support
With traditional software, support teams had to install the same version as the users and spend time trying to reproduce an issue based on unclear instructions from a user’s ticket. And it is sometimes useless as the issue depends on the environment. With well-designed data from a SaaS, your support teammate can browse all the recent activity of the user and see how the system responded and evolved through those interactions.
Maybe there was a known incident during this timeframe? Or maybe there is a known issue that the support team can identify through some pattern in the data? Also, your support team now has all the needed information to reproduce the user’s interactions, moreover on the same system. In my experience, support teams always made great use of the data to increase their efficiency as well as their knowledge of the system, highly reducing their need for help from the engineering teams in the long run. And whenever developers need to investigate, they also greatly benefit from this data to be more efficient.
In the optimization job example mentioned above, the support has now access to the history of the jobs for each user: they can identify which jobs had an issue even without clear explanations from the user’s support ticket. They can compare the job details to the known bug patterns and incident timeframe. They have enough data to send the same job manually to see if the issue is still here as well.
Truly agile product management
Agile and SaaS work well together. A key aspect of agility is the ever-on-going feedback loop. The use of data to provide insights during analysis and evaluation steps is quite obvious. I rarely saw a team including data in the testing phase but it can open a new range of possibilities!
Gathering data from your system allows you to perform testing at scale. For instance, if your app processes jobs, you can do a shadow release of a new feature and gather the new job results, even without sharing them with the users yet. You can then analyze the obtained data to assess the quality of your new feature. Data also enables approaches like A/B testing at scale. Those approaches can further reduce the duration of the feedback loop and increase the responsiveness and agility of your teams, supporting the creativity of your product teams and allowing them to make educated and data-backed decisions.
In the optimization job example of this article, we were able to release new features under the hood and activate them on some of our user’s jobs without returning the associated results. This way, we were able to identify issues early on without spending hours manually testing a large variety of inputs. This also allowed us to test the resource consumption of the new feature at scale, and adapt our infrastructure pro-actively. This helped ensure a clean public release.
Monitor what matters
I always had an issue with error monitoring of apps and services. Don’t get me wrong, having error-free services is a goal every tech team should pursue. But it can be overwhelming and draw your team into a frustrating never-ending loop of fixes. I have seen more errors linked to badly written code and without impact on the features than app-breaking ones. Should you fix those errors? Of course. Is it a priority? Probably not.
I often prefer a “functional monitoring” approach based on the gathered data as a first approach to monitoring and quality enhancement of services. The data you gather from your SaaS reflects the user experience. Maybe it is OK to have errors thrown in your app as long as the optimization jobs are correctly performed. On the other hand, you probably have broken features that don’t throw any errors. Your tech team should focus on what has more impact: My rule of thumb is that fixing the user experience is more important than cleaning your logs.
In the optimization job example, we created alerts based on the data we gathered. BI tools like Metabase have features to easily set it up. It allowed us to capture behaviors in a more relevant way. Maybe one specific user is encountering a lot of errors. It would not show in a global monitoring of several errors but you can easily catch it with SQL-based alerts. This approach allowed us to identify and prioritize issues to deliver fixes with much more impact than error fixes would have had.
The sky is the limit
I decided to showcase potential impacts on Support, Product, and Engineering as those are the departments in which I witnessed the most important differences between traditional software companies and successful SaaS companies. Of course, there are a lot of other areas that can benefit from access to data, such as Marketing and Engineering itself. What keeps on amazing me is how creative people can be when getting access to data: you can never anticipate how it will be used and this is why you must make sure you provide the clearest and easiest data to read, understand, and manipulate: the rest will naturally come from your teammates.

I am Mathieu Lamiot, a France-based tech-enthusiast engineer passionate about system design and bringing brilliant individuals together as a team. I dedicate myself to Tech & Engineering management, leading teams to make an impact, deliver value, and accomplish great things.
I seriously love your blog.. Pleasant colors & theme. Did you develop this site yourself?
Please reply back as I’m wanting to create my own site and want to know where
you got this from or what the theme is named. Kudos!
Hello, thanks!
I created the website based on this theme: THEME BASED ON: BUSINESS INSIGHTS BY THEMEINWP but I modified it with some refinements and customizations.