Table of Contents
Even small companies have data
Data can be a great asset for product-oriented companies, especially in Tech: it brings a bit of factual input in volatile, uncertain, complex, and ambiguous (VUCA) environments. A few companies understood this early on such as Facebook, Google, Netflix, and LinkedIn, a bit more than a decade ago. Since then, many “medium-sized plus” tech companies built their own data team or even department and they play a pivotal role in Product & Engineering within those companies.
What about small companies? What if you cannot invest to hire a data team or even a couple of data engineers? You probably already have data; it is just not managed by dedicated teammates. I am a fierce advocate of relying as much as possible on data (see my previous article From traditional software to SaaS: turn data into success).
Therefore, I don’t think tech leaders and teams should just ignore their data just because they don’t have data engineers: As we will see in this article, even in larger companies with dedicated data teams, the data is rarely only managed by data engineers: instead, the whole Engineering department, and also others are directly involved in the data management processes! Maybe you don’t need a data team to get started then.
Main challenges of Data leaders by DataGen
A few months ago, I read a great LinkedIn Post by Robin Conquer (DataGen) about the main challenges reported by Data leaders (in French only).
While this put words on challenges I observed and sometimes faced when working at the French unicorn fintech company Lydia, I also realized I was facing and tackling some of them now at WP Media even without a Data team. Let’s go through the steps we are taking, and that you could take as well, even without data engineers, to better manage your data so that your company can benefit more from it, and ultimately your developers as well in their daily tasks.
Data quality through developer ownership
With bad data, you pass on an opportunity to up your game.
Data you can’t trust is probably the worst data: it is at best useless, at worst misleading and it breaks the trust of your colleagues in the data the engineering department can provide. It might be good enough for your app to run because it might not need all the information to be accurate, but then, you pass on an opportunity to up your game.
To tackle the data quality issue, you should consider data as a feature of the product you work on: When developers understand that they are not just building features but also contributing to the overall health of the data ecosystem, they become more invested in maintaining high standards: data outputs of your app can be tested, enhanced and fixed just like any of its features.
To illustrate this, let’s take the example of user account deletion on an app: once the account is deleted, chances are you can just remove the related records in your database. However, knowing that the account existed and has been canceled at this date could be useful outside of the app itself. Here are a couple of examples:
- it can be used to measure and understand churn ;
- let’s suppose that something goes wrong with the cancellation of the subscription with the payment gateway. The user contacts your support as they are still being charged, but there is no trace anymore of this account.
Handling account deletion with a “deletion date” data rather than purely removing the records from the database could help here, but it will only be considered if the data from the app is considered as a feature of the product.
Database design for small companies: production-ready and human-readable
Companies with data teams can usually afford a dedicated architecture where explorable tables are fed from production tables, such as the Medallion architecture. I find this hard to set up and maintain for the engineering department without a data team, as this requires specific expertise, and the more complex your stack is, the more maintenance it will need.
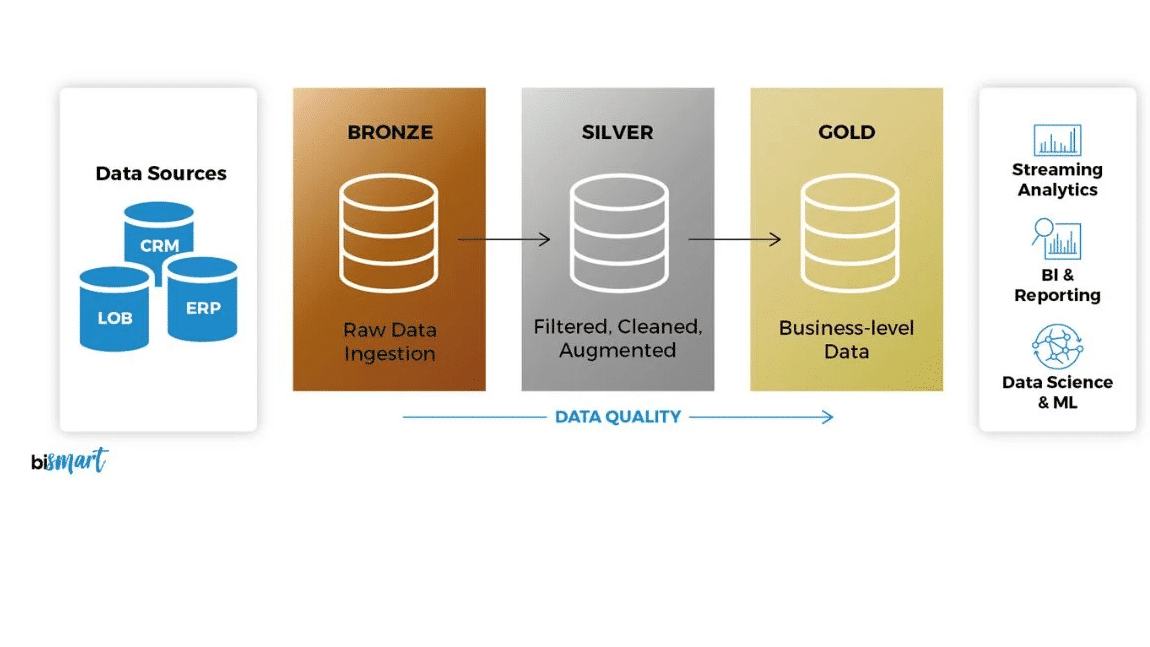
I prefer to design the production database so that it is human-readable and “ready for BI” as much as possible. In a perfect world, this is not a so good practice and it might not be always doable, especially in contexts where database optimization for production is key. But in my experience, even when the database suffers performance issues, this is not because the data is human-readable, but rather because of badly handled database design in the first place. Also, designing a human-readable database forces developers to design their database, and think about it like any piece of software they craft.
Many frameworks handle the data model behind the scenes, making the developer not necessarily aware of what is going on at the database level. Django is a good example of this: it can be tempting for a developer to define many small models for separation of concerns, as they can easily be joined in the app to reconstruct the whole useful object. On the other hand, one could also use a single model with many optional properties. Even if those might not be the best approaches, the framework makes them not that complex to work with. But then, if you ever have to look into the database and try to read it, you might have a hard time.
Encouraging developers to own the data they generate can lead to cleaner, more reliable, and readable data, ultimately supporting better decision-making across the company. This can usually be highlighted through bug fixing and investigations: clean, easy-to-use, and accurate data can greatly speed up the identification of issues and even monitor and test fixes. In my experience, this has been an efficient way to raise awareness about the power of data to development teams and the importance of making it easy to navigate.
The self-service approach
You don’t have a data team, so your non-technical teams likely have no one to ask to perform data analysis. Even if your engineers could do it, they already have a lot on their plate, and they might not be SQL experts anyway… The good thing is, after reading this article, now you have data that is understandable and navigable by humans!
Self-service analysis with no-code BI tools
A self-service approach to data empowers non-technical teams to access, analyze, and derive insights from data without relying on data analysts. To achieve this, you need a way for non-technical teammates to access and explore the data, and extract analysis from it, without having to write SQL or code. There are great tools out there to achieve this. My go-to is Metabase: it is an easy-to-use tool that allows you to explore data tables, execute SQL queries, build SQL queries with no code, and visualize results with nice graphs.
Just like every new tooling, consider introducing it with training sessions from the engineering team owning the data: this is a great way to explain to further foster ownership of the data for the developers and gather valuable feedback from non-technical users to understand what they would need, and ultimately iterate over the products so that they output better data.
Documented standard data models
Learning to navigate and explore data can be difficult for non-technical teammates, so it is key to make this process smoother for them. Documenting the main principles of the data model can be of great help: for instance, providing documentation including statuses used by the app and explicitly explaining useful fields like timestamps (created_at, etc.) can help non-technical teammates to approach the data.
One discouraging challenge is to start from scratch with every new database or product because nothing is similar to what they learned on the previous one. The same stands for developers themselves! Standardizing some aspects of your data models can therefore be very valuable for the self-service approach and for the overall quality of your data. Standardizing the use of created_at fields or having a go-to strategy for primary key (I recommend ULID) are good examples of generally applicable practices that can help both technical and non-technical teammates work with your company’s data.
Should production data be accessible?
In a perfect world, no. But if you can’t afford a dedicated data stack, you might not have the choice. Of course, write access to production data must be restricted; and some tables should also be restricted in read mode when they contain sensitive data for instance. (Metabase allows this!)
What about reading non-sensitive production data? The main issue that usually comes up is the risk of performance impact on the database: if someone executes a long and demanding query on production, this could impact users. This is a valid concern. However, in practice, I mostly saw it happening because the data model was badly designed in the first place, forcing teammates to join multiple tables to get basic information, over not-indexed columns, etc. So maybe this is a good way to expose the flaws of the database after all?
Of course, there are cases where the data model is as good as it can be, but the data is such that running exploration queries can be a threat to production. Separation of the production database and “BI” database is then a good solution. Without a dedicated data team, I am not fond of deploying a data stack and pipelines that require specific knowledge and expertise to set up and maintain. An approach that has been successful at WP Media was to build a “data service”: we have a simple Django app that receives API calls from our production apps, maybe do simple processing on the payload, and then stores the data in its database.
The main advantage of this approach is that it leverages the same technologies we use daily for our production apps: Django, API & Webhooks, and SQL databases. It also allows us to maybe add some processing outside of the production apps to possibly re-arrange the raw data before storing it. This is a homemade approach to a proper data stack that is easy to set up and maintain, with a low impact on production.
Fostering a data-oriented culture
Great, now you have tools and databases ready to be explored. This is a great enabler to build a data-oriented culture! But the rest is not about tooling or technical challenges, but mindset. Especially if your teams are not used to leveraging data in their daily work, it is important to frequently remind people of this possibility, push for it, gather and address feedback about difficulties to do so, and ultimately showcase success stories based on data-oriented choices.
Each department can find its own use for the data: from measuring the success of a marketing operation to identifying the points of friction in a product. When it comes to engineering, I find the following topics good candidates to introduce the use of data in daily tasks:
- Functional monitoring with alerting based on SQL queries: this can be used to identify unexpected data or abnormal database behavior variations and proactively fix potential issues.
- Bug identification after a defect has been reported.
- Fix/enhancement/release validation as it helps monitor the behavior of an update in production
As the benefits of being data-oriented become more and more visible, being data-oriented will become a habit and hence, a cultural value of your teams and company.

I am Mathieu Lamiot, a France-based tech-enthusiast engineer passionate about system design and bringing brilliant individuals together as a team. I dedicate myself to Tech & Engineering management, leading teams to make an impact, deliver value, and accomplish great things.
Comments