Table of Contents
Database table creation 101
Databases are used extensively in most tech-based services and have become a mandatory skill for most software engineering positions. Interacting with databases and tables is also effortless, even without knowing much about SQL. Many frameworks offer built-in methods to store, read, and search through structured databases. But this simplicity can lure engineers into overlooking the design of their database tables, which in turn can create useless complexity. In this article, I’ll share my very basic thinking and go-to references when I have to create or modify a structured database. This is a simple yet effective compilation of practical guidelines every software engineer should apply when working on designing database tables.
Why does database design matter?
When asking this question, or looking it up on Google, performance comes up. Indeed, systems and services are often supposed to handle increasing traffic and the database performance can become a bottleneck for the scalability and overall performance of your application. However, I believe this is not the number 1 reason why database design is important. I think database design is important because it is one of the entry points for a human to understand what your application does in general, or what it did in a particular case.
Think about onboarding a new developer on your app: you should probably provide some use cases and explain to them how the app behaves for each of them, step by step. If your app relies on a database, snapshots of the related data are usually an efficient and simple way to illustrate this. Well-structured databases and tables are one of the foundations of well-designed applications because they make them understandable and, hence sustainable. You are quite lucky if you never had a case of “Oh, your implementation does not work because you are reading the column status, but in fact, you want the column state“. I have seen this happen way too often, costing hours to developers and a lot of frustration: it has always been because of a not well-thought database design in the first place. Of course, you can document, comment, and so on. But you could just take 15 minutes before creating or modifying a table so that your model is self-standing.
Now, in case of a bug, you want to understand what happened. An easy-to-read and well-structured database should allow you to find everything you need quickly and easily, without ambiguity. Suppose your data model is self-standing and clear. In that case, this investigation can even be carried out by people outside the tech team: I worked for a company where the support team was able to investigate issues reported by users, and quickly identify what happened and whether or not some things needed to be fixed or if the issue had no lasting impact for instance. While avoiding context-switching for the tech team because they did not get pinged to assist the support team, a clear and self-standing data structure empowered the support team to autonomously perform complex tasks. This example shows how powerful a well-thought design can help your entire organization to be more efficient, and reduce frustration for all teammates.
Track time: creation and modification timestamps
My first action when creating a table is always to add a created_at timestamp column, and also a modified_at timestamp column (unless the table is append-only). As their name indicates, those columns store respectively the timestamp at which the row was created, and the timestamp at which it was modified last. I usually create an index on the created_at column as well.
And in many cases, those columns are not used within the codebase. Yet, they are, in my experience, the most useful columns for your organization: they are the first columns I filter on when I need to investigate a case or a bug report, or when extracting data for a business dashboard or a quick analysis for instance. This can be the key to finding the entry related to an issue reported by a user, identifying a regression following a release (especially if your team releases continuously), etc.
The cost of adding those columns is nothing compared to what you will gain. Moreover, many frameworks can handle those columns automatically (for instance Django). Your data can often be one of your best assets if you have a way to look into it: those timestamps provide you with a first step toward this as they allow you to build reporting, analysis, and alerting. (See: From traditional software to SaaS: turn data into success).
IDs: Make it simple
Now that those timestamps are created, your table needs a primary key. There are a lot of ways to generate IDs for primary keys, from a simple counter to a fully custom system. One can get into long and (not always) interesting discussions about why ULID is better than UUID (I already have an indexed created_at column, and it is human readable…), and so on. I tend to favor the separation of concerns: your primary key/ID is here to uniquely identify a record in your table, don’t try to do much more with it. Unless there is a very specific need for a specific design for your database (in which case, this article is not advanced enough for you anyway), just go with UUIDv4.
Database normalization
Now that you have timestamps and IDs for your records, you need to think about the actual data you want to store, and how to store it. There are many ways to store the same data, but identifying an understandable, performant, and evolutive structure often requires some thinking.
You should first list all the data you want to store. For instance, within an app handling orders, here are some data you probably need to store: object ordered, customer’s name, customer’s phone number, customer’s address, the status of the order, number of objects ordered, etc. The very basic approach would be to store all that information in a single record (a unique row within a single table). But this creates several inefficiencies: If the same customer places several orders, you would duplicate the customer’s name, address, and phone number in several records, which consumes storage space and might create difficulties in maintaining data consistency if the customer updates his phone number later on. Some customers might not add a phone number, so this column could be empty from time to time. Over time, one would need to add columns to support new features resulting in many rows partially filled. While this would work, it can get messy to maintain and perform analysis.
Of course, this is a very basic pitfall that most engineers would naturally avoid but it highlights the traps in which one can fall, especially for a database that is evolving and into which new features get added with time. I highly recommend the Wikipedia page about database normalization and always asking yourself the question “How deep does it make sense to go for my application?“. For instance, data that can be modified from a business perspective should not be duplicated across the database to ease maintenance, but going all the way to the sixth normal form makes the data hard to navigate manually for debugging or analysis purposes and can require many joins to retrieve the minimal usable data for your application, resulting in lower performances. In the case of complex projects where such a level of normalization is required, consider creating views to ease data reading and manipulation.
As a rule of thumb, the third normal form is often a good trade-off between readability/usability, maintainability, and performance. Keep in mind that the trade-off you choose when starting your application might not be relevant anymore one year later, as you add new features or as needs evolve. Thinking and designing your data as a product means that you should iterate frequently: re-evaluate your choices frequently and dare to reorganize your database when needed. The sooner the better, as migrations can get overly complex when done too late.
Do you need history? Think append-only!
A specific use-case of databases I have seen poorly done quite often is when history is needed. Going back to the ordering app mentioned above, if a customer updates his phone number, you probably don’t care about the previous data and you can just replace it (and update the modified_at field along the way, so that your customer service can understand why communications before that did not reach the customer!). But it could bring a lot of value to keep track of all the statuses the order went through and when: most e-commerce websites or delivery companies display a history of your order on their website for instance.
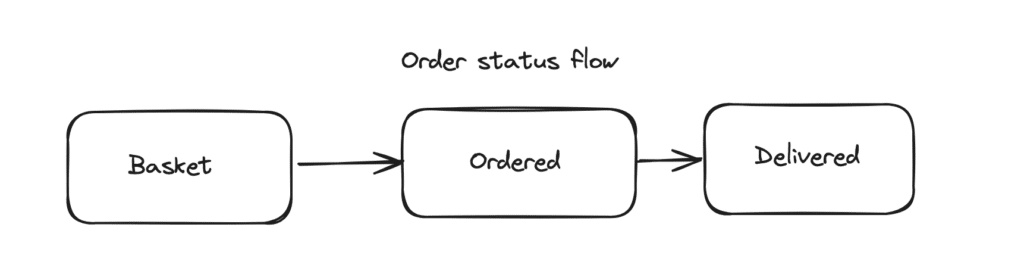
This is typically a feature not developed during the first version of the product, and added later. So you already have a database where the order’s status is updated every time it changes. How can you keep track of the history? The straightforward approach I have seen happen too many times is to add columns to the order table: one new column per status, to store the timestamp at which this status was reached. That’s it, it works! Well, you might face some issues later on…
What if your order lifecycle gets more complex? Maybe customers could ask for a refund, adding new statuses hence new columns to your table. Chances are just a few percentage of your orders will be refunded so those new columns would be mostly empty.
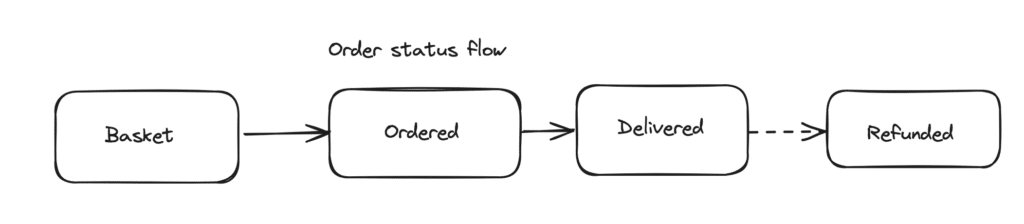
What if the order can go back to an already-reached status? Then, you would have to replace the timestamp, and hence lose part of the history you wanted to keep. As your application evolves, this model will become increasingly complex, hard to maintain, and full of edge cases, exceptions, and potential issues.
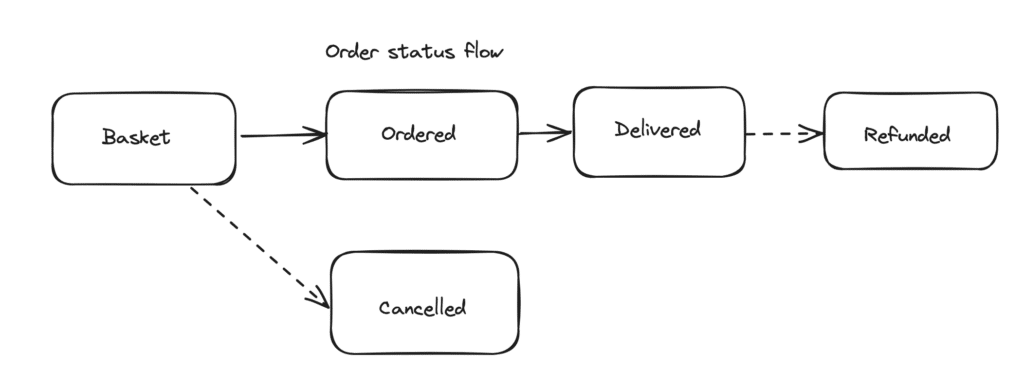
A preferable approach would have been to remove the status column in the order table and create a new append-only (also called ledger) table order_status with a foreign key reference to the related order. At every change of status, a new record is added to the order_status table with the new status (and the related created_at timestamp described above). This normalization process allows you to store any status flow for your orders. It is future-proof for eventual flow changes and it even allows a separation between mutable data related to the order (its status) and immutable data (object ordered, customer ID, etc.).
This normalization process has a little up-front cost as you need to implement the logic to handle this new data structure, but the gains are high. It appears easily as the right choice for such a situation if you take the time to think about the design of your database: If you think of your data as a product, you will identify such enhancements and optimizations early on and avoid technical debt at the core of your system.

I am Mathieu Lamiot, a France-based tech-enthusiast engineer passionate about system design and bringing brilliant individuals together as a team. I dedicate myself to Tech & Engineering management, leading teams to make an impact, deliver value, and accomplish great things.
Comments